
Zeyad Abdelrahim
AI Researcher
LLMs Are Mountains of Knowledge — We Just Need to Find the Peaks
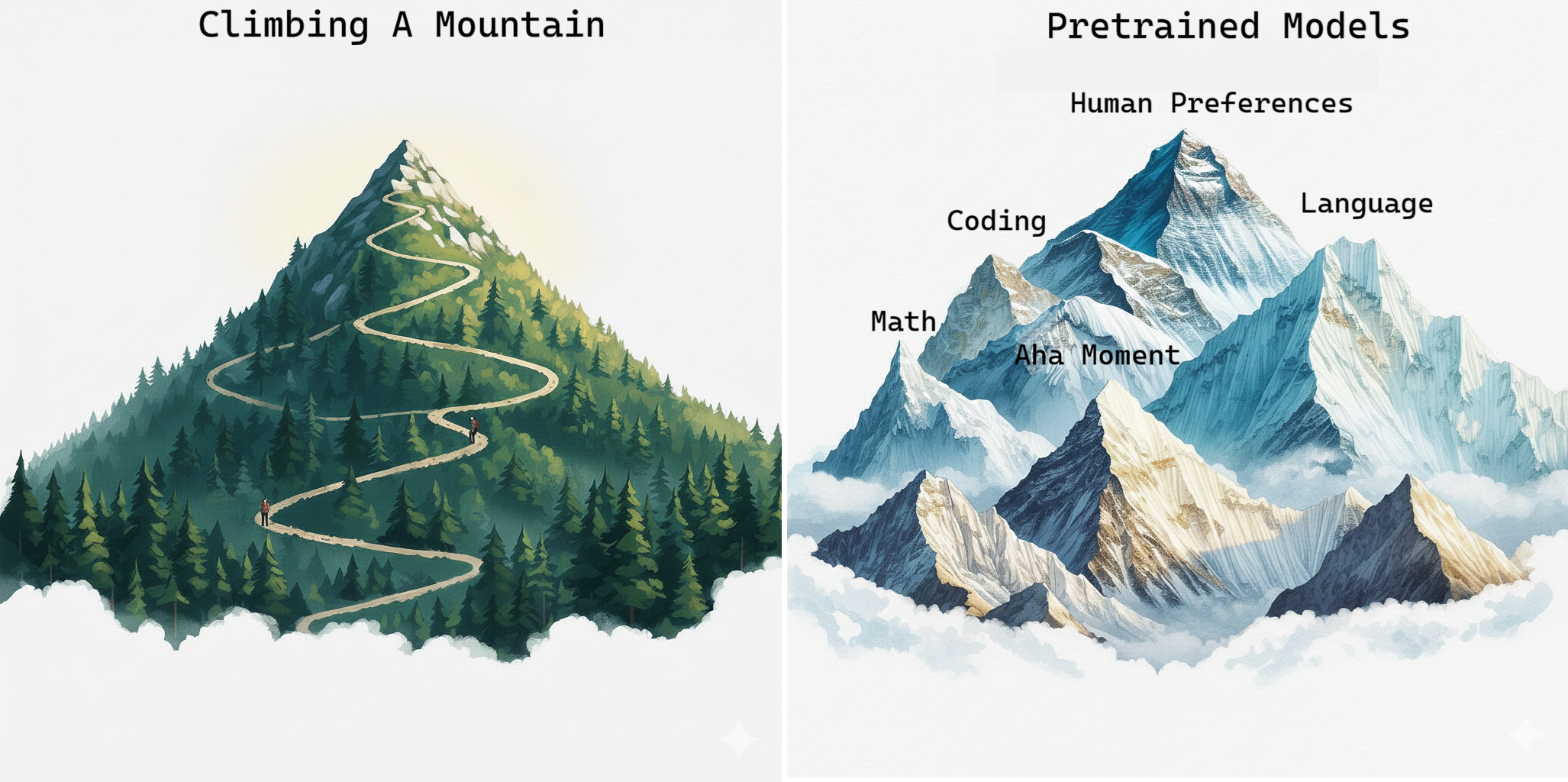
In this post, I explained my intuition/understanding of the difference between RL/SFT when finetuning a pretrained model, trying to understand why RL generalizes while SFT seems to memorize.
- 1